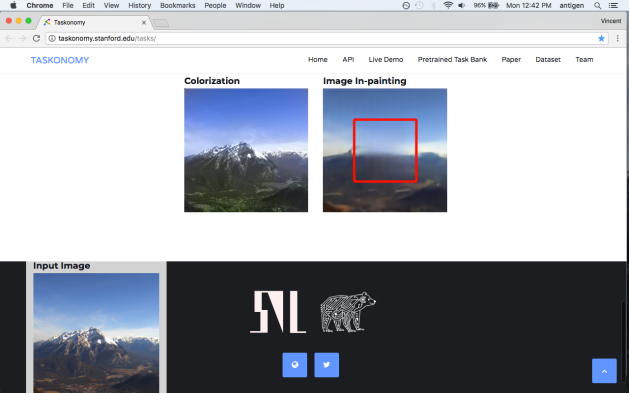
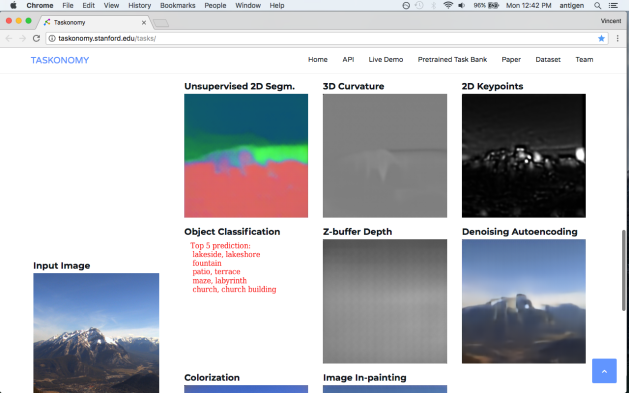
Malware < ————————————————————————— > Detector
Generator < ————————————————————————- > Discriminator
One network generates candidates and the other evaluates them. Typically, the generative network learns to map from a latent space to a particular data distribution of interest (benignware), while the discriminative network discriminates between instances from the true data distribution and candidates produced by the generator. The generative network’s training objective is to increase the error rate of the discriminative network (i.e., “fool” the discriminator network by producing novel synthesized instances that appear to have come from the true data distribution).